Image Classification with Vision Transformers

Introduction
It is a fact that Convolutional Neural Networks(CNN) have been dominant in Copmuter Vision tasks. However, ViT - AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE paper showed great results compared to SotA models. Here, we will dive deep enough to understand the Transformers architecure and apply the model to some practical tasks.
{cite}'voita2020nlpCourse'

The simplest model consists of two RNNs: one for the encoder and another for the decoder. Encoder reads the source sentence and produces a context vector where all the information about the source sentence is encoded. Then, decoder reads the context vector and generates output sentence based on this vector. The problem with such a model is that encoder tries to compress the whole source sentence into a fixed size vector. This can be hard, especially with long text inputs. It cannot put all information into a single vector without loosing some meaning.
Attention was introduced to overcome the shortcomings of the fixed vector representation problem. At each decoder step, it decides which source parts are more important. The encoder does not compress the whole input into a single vector - it gives context for all input tokens.
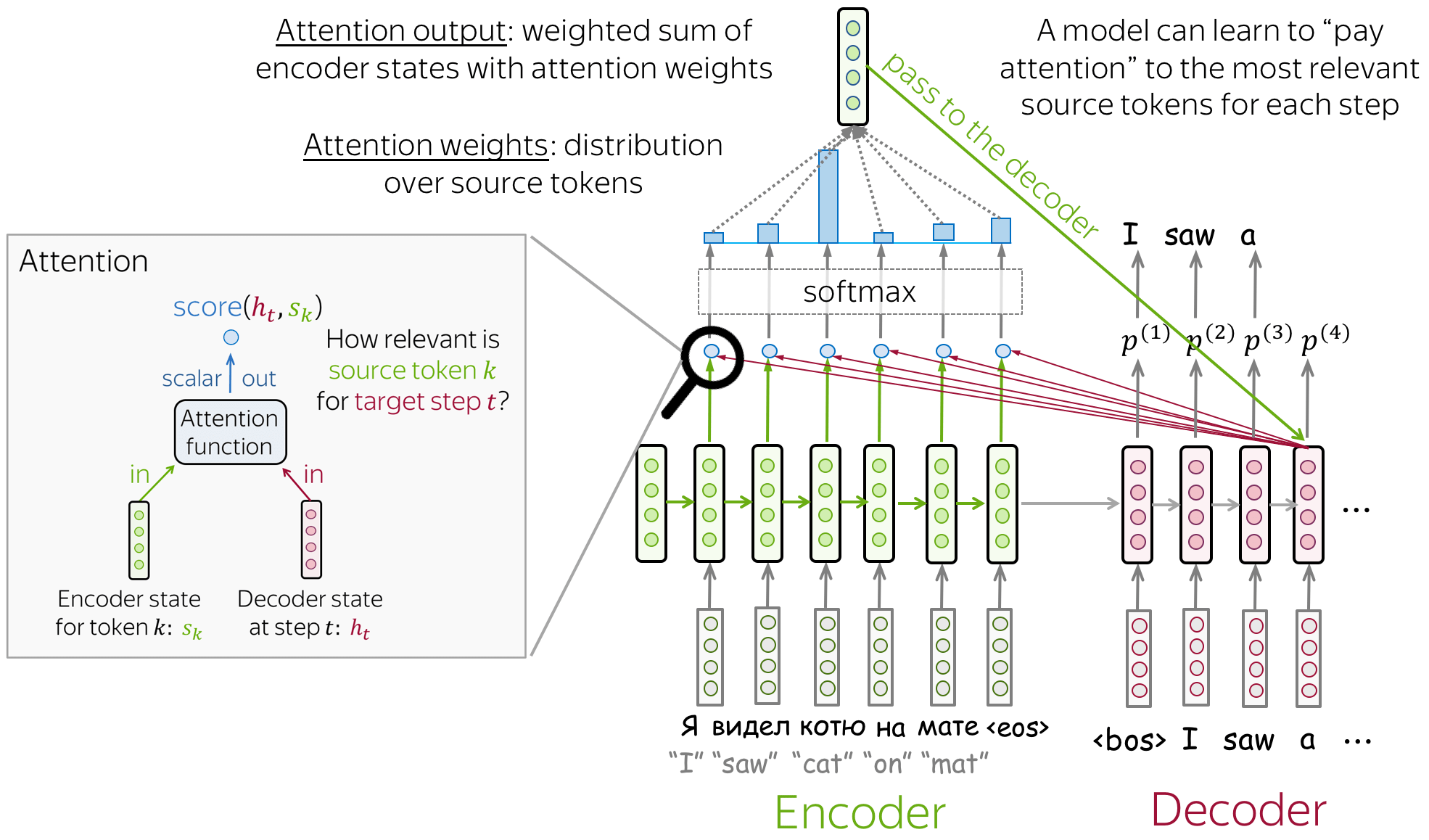
Image from voita2020nlpcourse
- Attention mechanism takes all encoder states and one decoder state as input
- Gives a score to the input (computes weights)
- Output from 2 are normalized using softmax function.
- Outputs weighted sum.

But, how the score is calculated? The simplest method is dot product of encoder states and a decoder state. Other methods are bilinear function and multi-layer perceptron which was proposed in the original paper. The main purpose of calculating the score is identifying similarity between the current input and all other inputs.
Transformer model was introduced in the paper Attention is All You Need in 2017. It uses only attention mechanisms: without RNN or CNN. It has become a go to model for not only sequence-to-sequence tasks but also for other tasks. Let me show you a demonstration of Transformer from Google AI blog post.
![]()
Let's take the sentence "The bank of the river." as an example. The word "bank" might confuse RNN as it processes the sentence sequentially and does not know whether the "bank" represents financial institution or the edge of the river untill the model reaches the end of the sentence. Unlike RNN, Transformer knows the context without reading the whole sentence as it's encoder tokens interact each other and give context to the words. In the above example, it is clear that at each step tokens exchange information and try to understand each other better.
The main part of the model is self-attention mechanism. The difference between self-attention and simplified attention is the prior has trainable weights.
$$query = W^qx_i\newline key = W^kx_i\newline value = W^vx_i$$
As shown in the example above, we calculate query, key and value for every input token. Output of self-attention is calculated like simplified attention with slight differences:
$$Attention(q,k,v) = softmax(score)v\newline$$ Here $$score = \frac{qk^T}{\sqrt{d_k}}$$
The reason why we are using scaled dot-product in attention score is to ensure that the dot-products between query and key do not grow too large for large $d_k$.